数据挖掘 |
您所在的位置:网站首页 › 数据挖掘 统计学 › 数据挖掘 |
数据挖掘
|
前言
描述数据的统计学学意义是大数据分析的挖掘的基础,它包括数据的收集、整理、显示,对数据中的有用信息的 提取和分析,有利于我们更好地利用数据探索数据背后蕴藏的关系,下面是一些用来分析的统计量: 集中趋势的特征值: 算术平均数、调和平均数、几何平均数、众数、中位数等,其中均数适用于满足正态分布和对称分布的数据,中位数适用于所有的分布类型。 离散趋势的特征值:全距、内距、平均差、方差、标准差、标准误、离散系数。其中标准差、方差适用于正态分布的数据,标准误差实际上反映了数据偏离正态分布的程度。 工具:spss statistics22 数据来源:第15届华为杯研究生数学建模大赛C题 1、 频数分析,多用于离散数据,了解变量的取值状况,把握数据的分布特征。 频数:变量值落在某个区间中的次数。百分比:各频数占总样本数的百分比。有效百分比:各频数占有效本数的百分比。累计百分比:各百分比逐级累加起来的结果。2、绘制统计图,直接客观的刻画数据,展示变量的取值情况。 这里仅以vicinity这个变量为例,以从表中得知,数据的取值有三个:0、1、-9(未知),对于未知(值为-9)的数据几乎可以忽略不计(占比为 0%),因此在对数据进行挖掘分析之前,先把这种数据处理成0\1取值的数据,尽可能降噪。处理这种少量的奇异数据主要有2种方法: 1)随机0\1处理 2)通过对数据进行语义上的处理,即依据互联网及其相关的权威解释进行人工处理。实际上在处理的过程中可以多种方式结合。
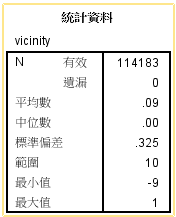
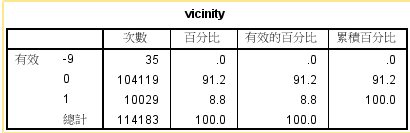
表中对4个存在遗漏数据的单变量的统计分析,对于缺失的值可以采取部分语义处理和部分随机处理的方式:对于重大事件,即可溯源的事件,可根据互联网上提供的资料给予补充;对于不可溯源的数据,可使用 均值替代法、回归填补法、期望最大法进行缺失值得填补,那么具体使用哪种方法进行填补的首要任务是先探索数据规律。 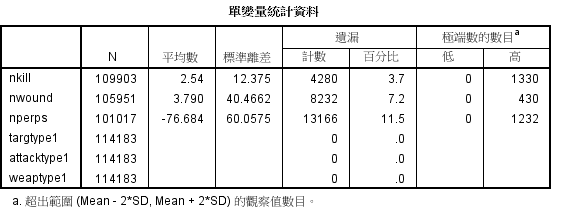
绘制4个缺失值较多的变量,进行散点绘图分析: 
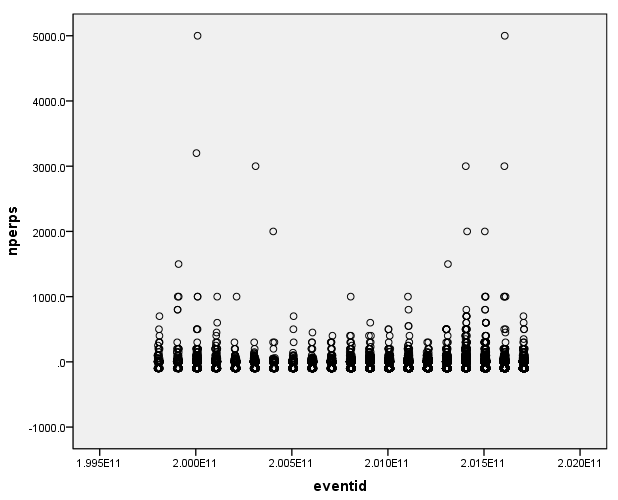
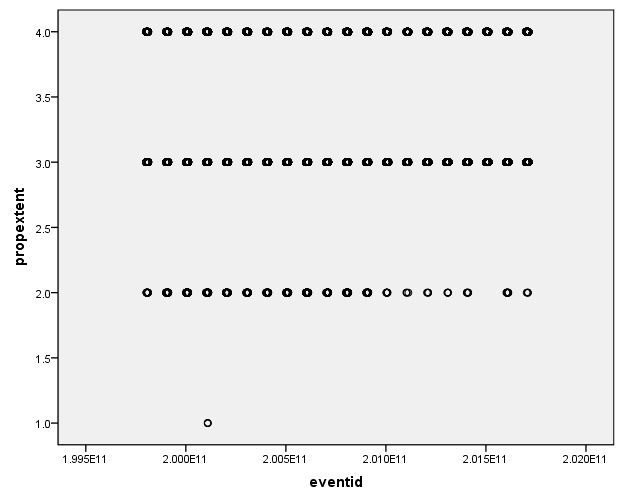
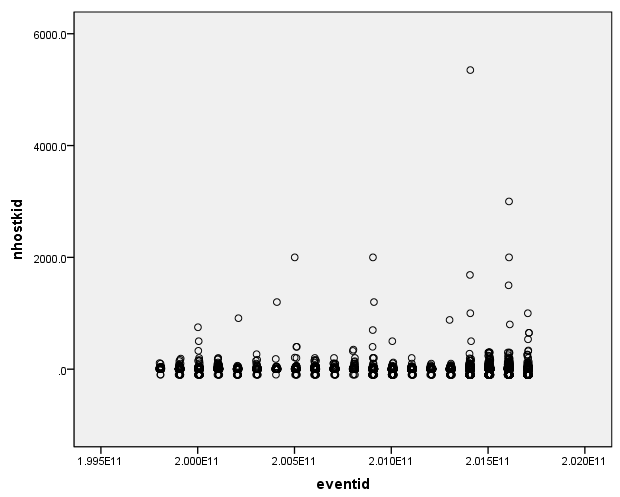 观察4个变量的散点分布情况:nkill变量大部分集中在0-500之间,整体分布在0-1000之间,存在2个偏离较大的点;nperps变量大部分集中在0-3000之间,整体分布在0-3000之间,存在3个偏离较大的点;propextent变量大部分集中在值为2、3、4上,存在1个孤立的点;nhostkid变量整体部分在0-2000之间,存在2个偏离较大的点。
由于偏离较大的点会有以下4个弊端:
观察4个变量的散点分布情况:nkill变量大部分集中在0-500之间,整体分布在0-1000之间,存在2个偏离较大的点;nperps变量大部分集中在0-3000之间,整体分布在0-3000之间,存在3个偏离较大的点;propextent变量大部分集中在值为2、3、4上,存在1个孤立的点;nhostkid变量整体部分在0-2000之间,存在2个偏离较大的点。
由于偏离较大的点会有以下4个弊端:
增加了误差差异,并降低了统计测试的能力如果异常值是非随机分布的,则可以降低正态性可能影响具有实质意义的估计可能影响回归、方差分析等统计模型假设的基本假设。
因此在填补缺失值之前需要剔除异常值,。 使用回归分析的方法的前提是数据对象得先满足回归分析的基本假设如下: 1、随机误差项是一个期望值或平均值为0的随机变量;2、对于解释变量的所有观测值,随机误差项有相同的方差;3、随机误差项彼此不相关;4、解释变量是确定性变量,不是随机变量,与随机误差项彼此之间相互独立;5、解释变量之间不存在精确的(完全的)线性关系,即解释变量的样本观测值矩阵是满秩矩阵;6、随机误差项服从正态分布。 如下是对以上4个变量数据规律的探索,发现4个变量的分布 都不满足正态分布: 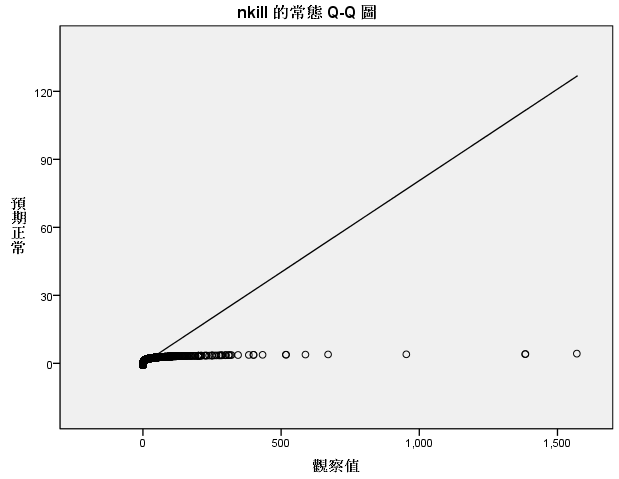
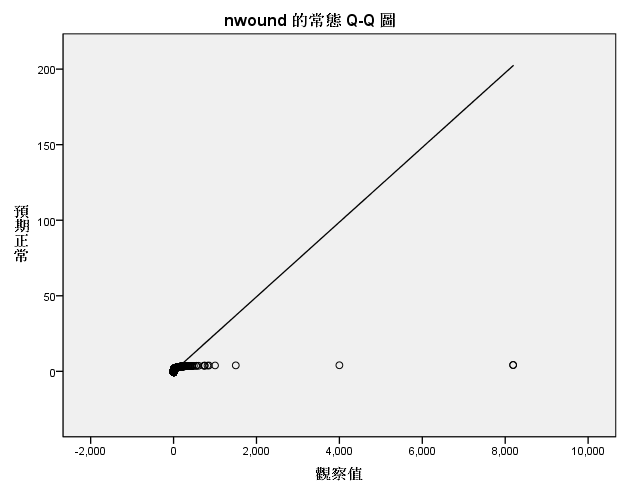
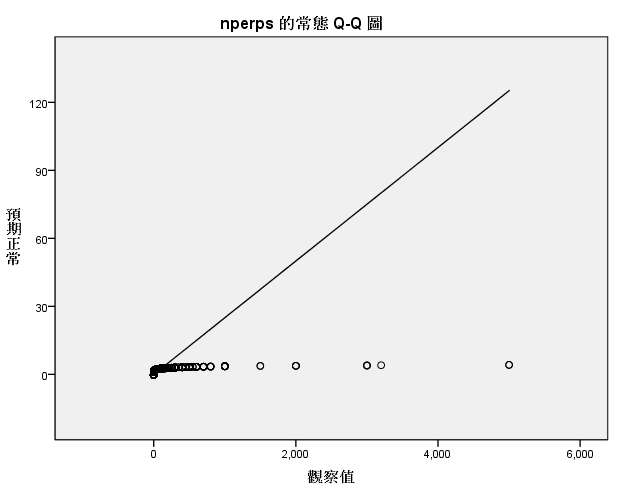
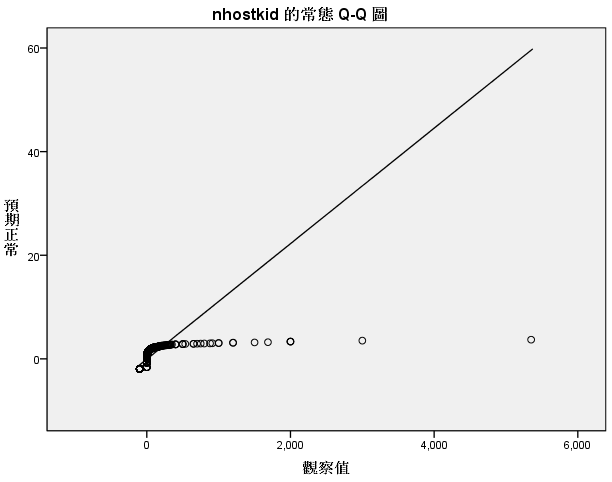
因此,这4个变量的填补都不能使用回归分析的方法进行填补。 利用最大期望法来进行缺失值的填补:
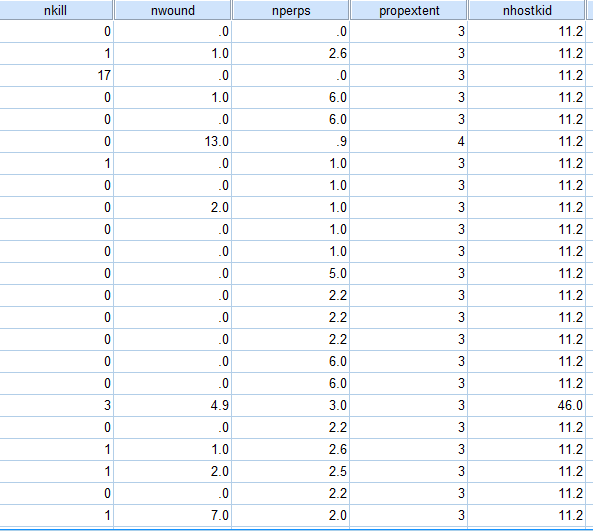
|
【本文地址】
今日新闻 |
推荐新闻 |